Workday Workday-Pro-Integrations Workday Pro Integrations Certification Exam Exam Practice Test
Total 109 questions
Workday Pro Integrations Certification Exam Questions and Answers
Refer to the following scenario to answer the question below.
You have configured a Core Connector: Worker integration, which utilizes the following basic configuration:
• Integration field attributes are configured to output the Position Title and Business Title fields from the Position Data section.
• Integration Population Eligibility uses the field Is Manager which returns true if the worker holds a manager role.
• Transaction Log service has been configured to Subscribe to specific Transaction Types: Position Edit Event.
You launch your integration with the following date launch parameters (Date format of MM/DD/YYYY):
• As of Entry Moment: 05/25/2024 12:00:00 AM
• Effective Date: 05/25/2024
• Last Successful As of Entry Moment: 05/23/2024 12:00:00 AM
• Last Successful Effective Date: 05/23/2024
To test your integration, you made a change to a worker named Jeff Gordon who is not assigned to the manager role. You perform an Edit Position on Jeff Gordon and update their business title to a new value. Jeff Gordon ' s worker history shows the Edit Position Event as being successfully completed with an effective date of 05/24/2024 and an Entry Moment of 05/24/2024 07:58:53 AM however Jeff Gordon does not show up in your output.
What configuration element would have to be modified for the integration to include Jeff Gordon in the output?
After you transfer ownership of an Integration System to an ISU, what other component, if it exists, must you transfer ownership of to ensure the integration continues to run in an automated fashion?
Refer to the following scenario to answer the question below.
You have been asked to build an integration using the Core Connector: Worker template and should leverage the Data Initialization Service (DIS). The integration will be used to export a full file (no change detection) for employees only and will include personal data. The vendor receiving the file requires marital status values to be sent using a list of codes that they have provided instead of the text values that Workday uses internally and if a text value in Workday does not align with the vendors list of codes the integration should report " OTHER " .
What configuration is required to output the list of codes required from by the vendor instead of Workday ' s values in this integration?
You have an existing EIB that you configured with a filename sequence generator that is associated with the EIB in the Deliver section. However, after testing the EIB, you notice that the filename is not using the configured sequence generator.
What is causing the sequence generator to not be used?
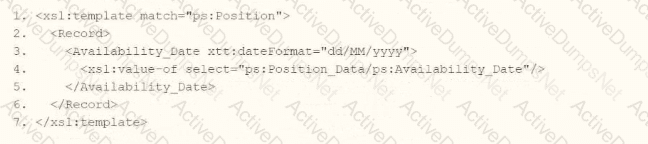
You need the integration file to generate the date format in the form of " 31/07/2025 " format
• The first segment is day of the month represented by two characters.
• The second segment is month of the year represented by two characters.
• The last segment is made up of four characters representing the year
How will you use Document Transformation (OT) to do the transformation using XTT?
Options:



You have an existing Core Connector: Organization (non-IS) integration that sends organization data to an external vendor. The vendor now requires a specific Legacy ID for each organization to be added to the output. A calculated field that generates this Legacy ID already exists in the tenant.
What is the high-level workflow order you would follow to add this calculated field to the output of the integration?
When creating an XSLT file to transform the XML output of an EIB, you must have the XSL namespace. What other namespace(s) do you need to process any part of the source XML file?
Refer to the following scenario to answer the question below.
An external system needs a file containing data for recent worker job changes. They would like to receive a file routinely at 5:00 PM Eastern Standard Time, every 48 hours. The file should show job changes since the last integration run.
What is the recurrence type of the integration schedule?
What is the purpose of a namespace in the context of a stylesheet?
What task is needed to build a sequence generator for an EIB integration?
What option for an outbound EIB uses a Workday-delivered transformation to output a format other than Workday XML?
After configuring domain security policies, what task must you run to ensure the most recent changes go into effect?
The following XML code was generated through a RaaS that will be used in an EIB.


Within a template that matches on wd:Report_Entry, what XPath expression do you use to select the value of the Relationship_ID element?
Refer to the scenario. You are configuring a Core Connector: Worker integration with the Data Initialization Service (DIS) enabled. The integration must extract worker contact details and job information, including a calculated field override that determines phone allowance eligibility.
While testing, the output contains no records, and the Messages tab shows exception logs stating you don ' t have access to the Exempt field. You note this is the same field being used for Population Eligibility in the integration.
What must you configure to resolve this security issue?
Which features must all XSLT files contain to be considered valid?
What is the relationship between the Integration System User (ISU), Integration System Security Group (ISSG), and domain security policies?
A vendor needs an EIB that uses a custom report to output a list of new hires and the date they are eligible for benefits. You have been asked to create a calculated field that adds each worker ' s hire date + 85 days and displays the result in YYYY-MM-DD format.
Which calculated field functions do you need to accomplish this?
Refer to the following scenario to answer the question below.
You need to configure a Core Connector: Candidate Outbound integration for your vendor. The connector requires the data initialization service (DIS).
The vendor needs the file to only include candidates that undergo a candidate assessment event in Workday.
How do you accomplish this?
Refer to the following XML to answer the question below.
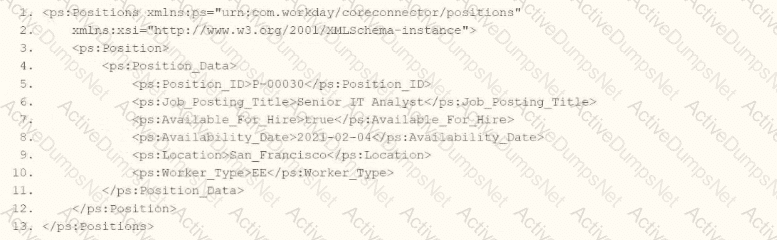
You need the integration file to format the ps:PositionJD field to 10 characters and report any truncated values as an error.
How will you start your template match on ps:Position to use Document Transformation (DT) to do the transformation using ETV with your truncation validation?
Options:




You are configuring the Core Connector: Location to send location data to a new global facilities management system. You must meet three specific requirements:
Task A: The facilities system requires that in addition to the default public address, the private address should also be included.
Task B: The facilities system uses the status codes “A” for Active and “I” for Inactive. You need to translate Workday’s “Active” and “Inactive” values from the Location Status field.
Task C: The facilities system requires a “Building Manager” value. You have already built a Calculated Field that retrieves the Facilities Manager role for each location, and you need to send this data in the integration.
How do you configure these tasks in the integration system?
What XSL component is required to execute valid transformation instructions in the XSLT code?
As of May 1, 2024 Brian Hill ' s annual salary is $60,000.00. On May 13, 2024 Brian Hill received a salary increase and data was entered into Workday at 2:00 PM the same day. The new salary amount is set to $90,000.00 with an effective date of May 10, 2024.
Run #1
Core Connector: Worker Integration System was launched as an ad-hoc manual run on May 13, 2024.
As of Entry Moment: 05/11/2024 2:00:00 PM
Effective Date: 05/11/2024
Last Successful As of Entry Moment: 05/09/2024 2:00:00 PM
Last Successful Effective Date: 05/09/2024
What will be the expected output in the Run #1 of the Core Connector: Worker Integration System?
You are configuring a monthly schedule for an EIB integration that runs on the last day of each month.
What is the maximum end date you can use in this configuration?
How many integration systems can an ISU be assigned to concurrently?
What are the two valid data source options for an Outbound EIB?
Refer to the following scenario to answer the question below.
An external system needs a file containing data for recent worker job changes. They would like to receive a file routinely at 5 PM eastern standard time, every 48 hours. The file should show job changes since the last integration run.
What is the run frequency of the integration schedule?
Refer to the following scenario to answer the question below.
You are configuring a Core Connector: Worker integration to send data to a new external compliance and certification tracking vendor. You have begun to configure the connector with the Data Initialization Service (DIS) enabled. Your goal is to extract worker qualification data, but the vendor has three specific requirements:
The file must only include Active workers who are in the “Clinical Staff” Job Family.
The vendor has specified that for each worker’s Education data, they only want to receive the Institution Name, Institution Type and Degree.
The vendor requires a custom “License ID” that must combine the Certification Name and Issuing State, for example, “RN-CA”. A Calculated Field that provides this custom “License ID” already exists in the tenant.
During testing, using a Full File run, the output file is missing all education-related information, even though you believe you have initially configured field attributes such as Institution Name, Institution Type and Degree in the Configure Integration Field Attributes step. Additionally, you confirmed that the Worker Qualification Data Section is marked as Include in Output.
What should you do to resolve this issue?
Refer to the following scenario to answer the question below.
You need to configure a Core Connector: Candidate Outbound integration for your vendor. The connector requires the data initialization service (DIS).
The vendor requests additional formatting of the candidate Country field. For example, if a candidate ' s country is the United States of America, the output should show USA.
What steps do you follow to meet this request?
When creating an ISU, what should you do to ensure the user only authenticates via web services?
A benefits provider requests a file containing updated compensation data from your Workday tenant. They want to receive this file at exactly 5:00 PM Eastern Time every weekday, but not on weekends. The file should include only compensation changes that occurred since the last integration run.
How should you configure the run frequency of the integration schedule to meet these requirements?
What items must a report have for you to use it as a data source for an integration?
Refer to the following XML to answer the question below.

You are an integration developer and need to write XSLT to transform the output of an EIB which is making a request to the Get Job Profiles web service operation. The root template of your XSLT matches on the < wd:Get_Job_Profiles_Response > element. This root template then applies a template against < wd:Job_Profile > .
What XPath syntax would be used to select the value of the wd:Job_Code element when the < xsl:value-of > element is placed within the template which matches on < wd:Job_Profile > ?
Total 109 questions