UiPath UiPath-SAIAv1 UiPath Specialized AI Associate Exam (2023.10) Exam Practice Test
UiPath Specialized AI Associate Exam (2023.10) Questions and Answers
What are all the ways to deploy Al Center?
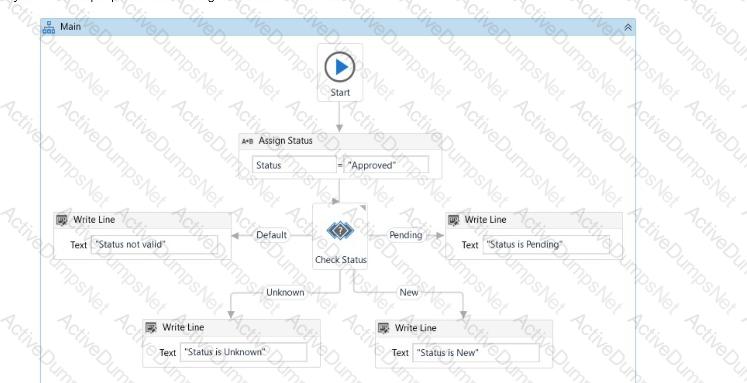
What will be displayed in the Output panel after running the workflow below?
What is the order of steps for automatically retraining and deploying a Document Understanding ML Model in Al Center with data from Document Validation Action?
Instructions: Drag the steps found on the "Left" and drop them on the "Right" in the correct order.


 A screenshot of a computer
AI-generated content may be incorrect.
A screenshot of a computer
AI-generated content may be incorrect.What are the mandatory activities to be included in an automation workflow to allow a remote knowledge worker to pick up an action that validates the extracted data in the form of a Document Validation Action?
Having the following Rules defined in the Taxonomy Manager for Billing Address field.
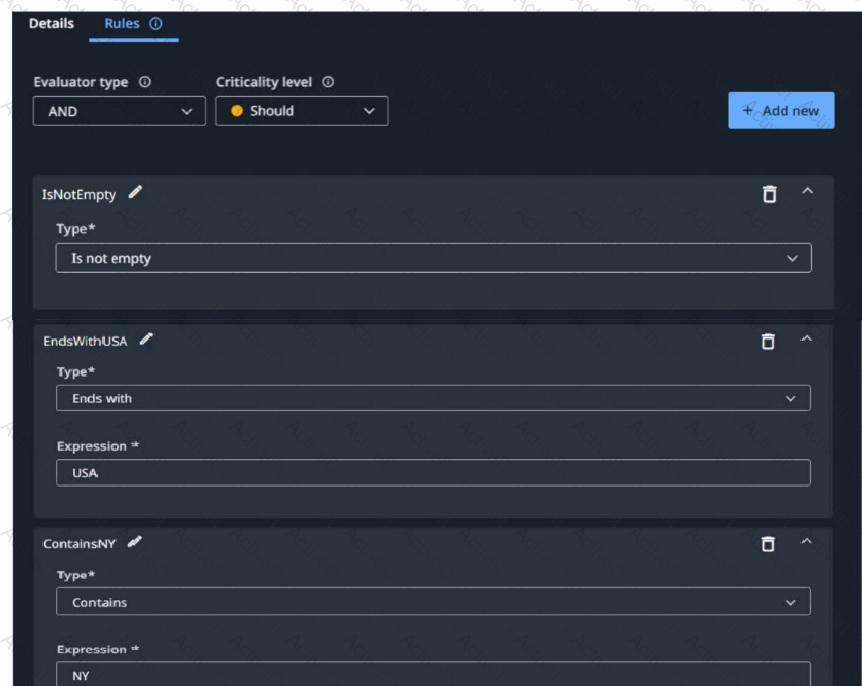
At the data extraction step. 42 W 80th St. West New York, NJ 1234, USA have been extracted (or the Billing Address field. When processing a Invoice using the DU process what will happen in (he Validation Station after data extraction step?
Which of the following is a best practice when choosing a UiPath ML (Machine Learning) Extractor?
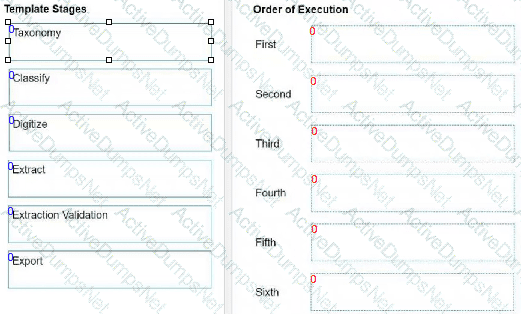
What is the correct execution order of the Document Understanding template stages?
Instructions: Drag the stages found on the "Left" and drop them on the "Right” in the correct order.

When creating a training dataset, what is the recommended number of samples for the Classification fields?
What is supervised learning?
What are the languages supported by the generic Document Understanding ML Package?
What will be the behavior of the process if, during design time, the property ValidateUnconnectedNodes is set to True on a flowchart and a Log Message activity from this flowchart is not connected to any other node?
Which generic ML Package should be used when the document type you are using is not part of the out of the box models?
What is DOM in the context of Document Understanding?
For what type of documents is it recommended to use the RegEx Based Extractor?
Which of the following extractors can be used for Data Extraction Scope activity?
What does a UiPath Communications Mining taxonomy include?
How do you choose the appropriate document processing methodology?
What is a characteristic of an Orchestrator Asset?
Having the taxonomy in a file, shared and updated across multiple projects, what is the most convenient way to load it in a UiPath Studio project?
Which of the following is a type of communication that is typically interpreted by UiPath Communications Mining?
Which of the following best describes UiPath Document Understanding?
What will be the outcome when executing a Try Catch activity with a sequence placed within the Try section and no Catches section present?
What are the main components of a digital business process?
What is the role of the dispatcher in the Document Understanding Process?
When using UiPath Studio's publishing options, which location(s) can automation projects be published to?
What is one of the main purposes of connecting Robots to Orchestrator?
What is the role of connections in the UiPath Integration Service?
What is the definition of Deep Learning?
Which environment variable is relevant for Evaluation pipelines?
On at least how many different pages should a regular field be labeled in Data Manager before Exporting the labeled documents to Al Center?
What happens to your document and the process of pre-labeling when you choose the "Predict" option from the "Predict" dropdown in Document Manager?
What does the following expression do?
subTotalAdditions.Select(Function(field) CDec(documentFields(field))).ToList.Sum() + subtotal
What differentiates UiPath Communications Mining general fields trained from scratch from general fields that are pre-trained?
Which of the following scenarios is a good candidate for using Document Understanding Cloud APIs with synchronous calls?
What is the main purpose of the Document Understanding Process template in UiPath Studio?
What is the purpose of the "Explore" phase in UiPath Communications Mining?
A developer intends to incorporate a Flow Switch activity within a Flowchart. What is a characteristic of this activity?
What fields are available when creating an Al Center project?
What is the purpose of the generative classifier?
What is the function of the Immediate Panel in UiPath Studio during the debugging process?
What additional information can be included in the exported data, apart from the extraction results?
Which is a high-level view of the tabs within an AI Center project?
Why is it important to understand the potential value UiPath Communications Mining can enable prior to training?
What are the available options for Scoring in Document Manager, that apply to string fields only?
Which are the the minimum required inputs in order to configure the Validation Station as an attended activity?
What can be done in the Reports section of the dataset navigation bar in UiPath Communication Mining?
For which version(s) from Out-of-the-Box ML Packages minor versions is the download functionality available?
What is the main difference between an array and a list in UiPath?
Which filter option should be used for the For Each File in Folder activity to iterate through all the Microsoft Word documents in a local folder?
What does the Train stage of the Document Understanding Framework do?
Which UiPath Studio activity creates a Data Labeling Action in UiPath Action Center?
What are the options available in the Export Now tab of the Export Files dialog box in Document Manager?
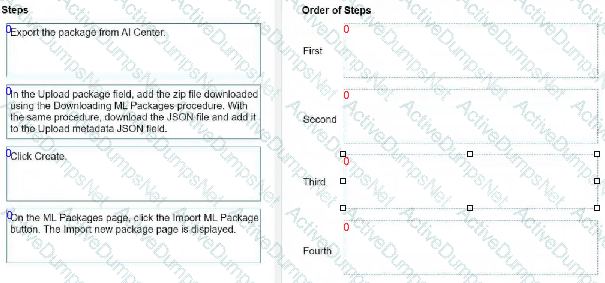
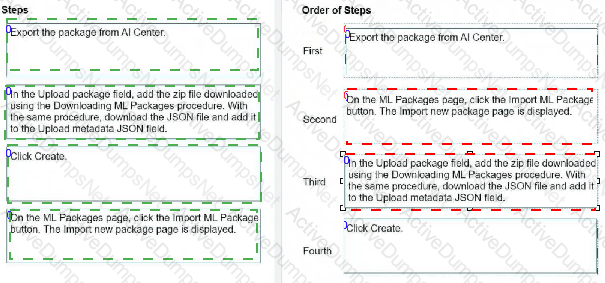
What is the correct order of uploading a package exported from UiPath AI Center?
Instructions: Drag the steps found on the "Left" and drop them on the "Right" in the correct order.
 A screenshot of a computer
AI-generated content may be incorrect.
A screenshot of a computer
AI-generated content may be incorrect.When a parent label is deleted in UiPath Communications Mining, what happens to the training data tor that label?
What can be done in the Reports section of the dataset navigation bar in UiPath Communication Mining?
Which of the following time periods can be selected when viewing Trends in UiPath Communications Mining?
Which of the following time periods can be selected when viewing Trends in UiPath Communications Mining?
In which of the following scenarios, the ML Classifier is the only recommended classifier to be used, according to best practice?
Which scenario would be best accomplished using unattended automation?
What is the role of the Taxonomy Manager?
What is the order of the steps needed to create a new Document Type using all the organization levels in the Taxonomy?
Instructions: Drag the Description found on the left and drop on the correct Step found on the right.


Given the following scenario:
• You have a trained version of the Document Understanding Model with 1000 pages called v22.10.0.1.
• You have an evaluation dataset of 100 pages that gave a score of 0.72 for v22.10.0.1.
• The business team labeled 800 pages and they ask for an increment of the Model that would contain all 1000+800 pages.
What is the first recommended pipeline run configuration to create the new version?
Which feature should be used to inspect the available versions for activities employed within a workflow?
Which UiPath Communications Mining model performance factor relates to the proportion of messages in the dataset that have informative label predictions?
How many types of synchronization mechanisms exist in the Document Understanding Process to prevent multiple robots to write in a file at the same time?2
Who is responsible for devising a strategy to prioritize processes during the Business Case and Technical Validation phase?
Which of the following best describes the primary purpose of the Quality of Service (QoS) functionality in UiPath Communications Mining?
Which are all the options for managing ML Skills?
Which of the following OCR (Optical Character Recognition) engines is not free of charge?
Which UiPath Communications Mining model performance factor assesses the proportion of the entire dataset that has informative label predictions?
What information should be filled in when adding an entity label for the OOB (Out Of the Box) labeling template?
What is the difference in scope between variables and arguments in UiPath?
Which of the following are unstructured documents?
What new capability has been introduced for processing unstructured documents in the 2023.10 release?
Which of the following is an indicator that sufficient training has been completed for a model in UiPath Communications Mining?
When dealing with variable-length data, or data spanning over multiple pages of the document (e.g. item tables), what is the recommended data extraction methodology to be used?