Microsoft DP-700 Implementing Data Engineering Solutions Using Microsoft Fabric Exam Practice Test
Implementing Data Engineering Solutions Using Microsoft Fabric Questions and Answers
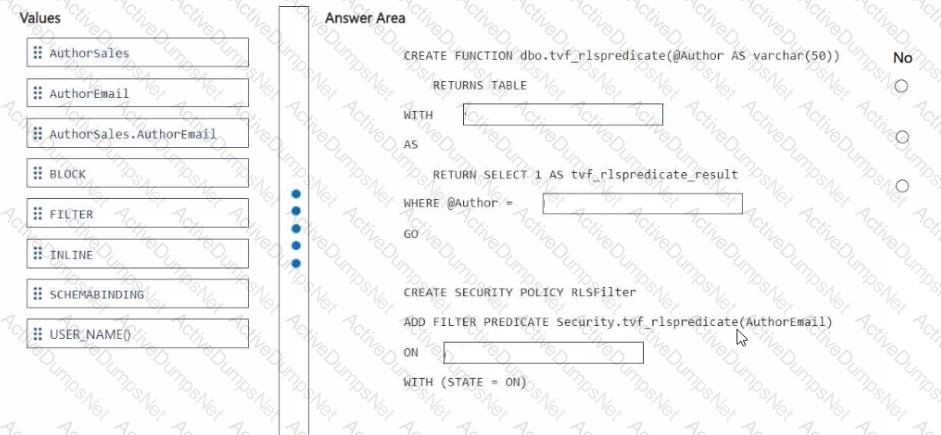
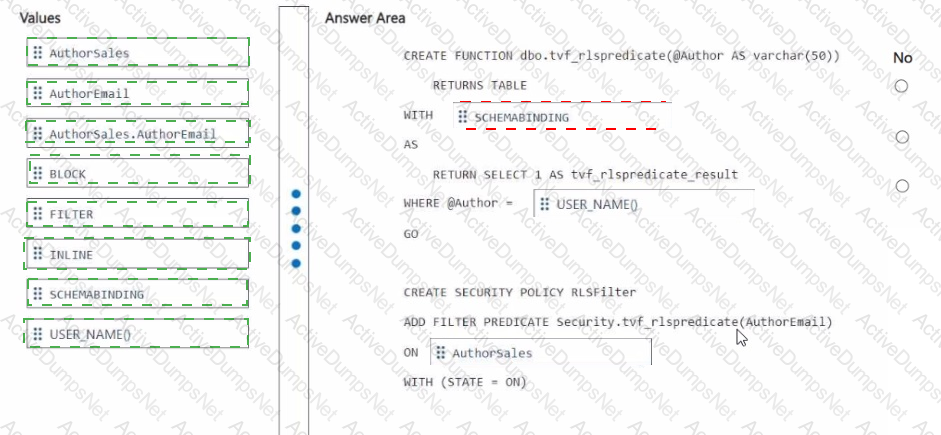
You need to ensure that the authors can see only their respective sales data.
How should you complete the statement? To answer, drag the appropriate values the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content
NOTE: Each correct selection is worth one point.
You need to ensure that processes for the bronze and silver layers run in isolation How should you configure the Apache Spark settings?
What should you do to optimize the query experience for the business users?
You need to implement the solution for the book reviews.
Which should you do?
You need to create a workflow for the new book cover images.
Which two components should you include in the workflow? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You need to resolve the sales data issue. The solution must minimize the amount of data transferred.
What should you do?
HOTSPOT
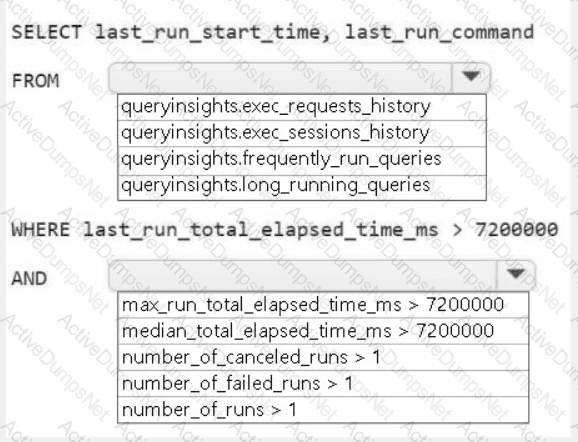
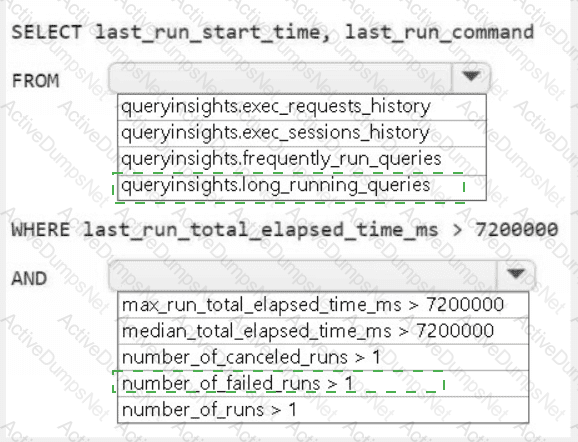
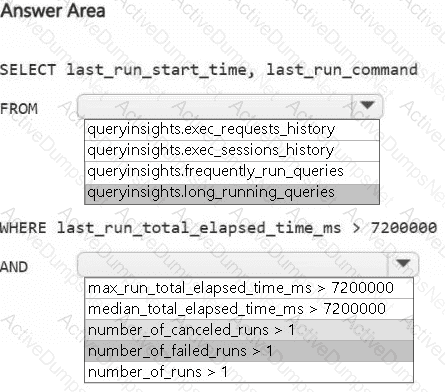
You need to troubleshoot the ad-hoc query issue.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
 A screenshot of a computer Description automatically generated
A screenshot of a computer Description automatically generatedYou need to ensure that the data analysts can access the gold layer lakehouse.
What should you do?
You need to recommend a solution to resolve the MAR1 connectivity issues. The solution must minimize development effort. What should you recommend?
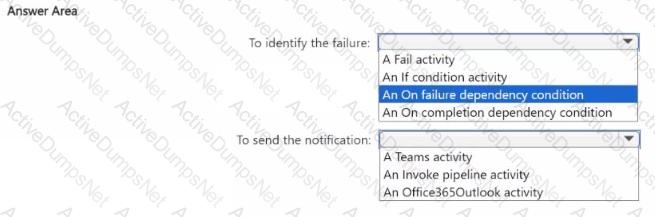
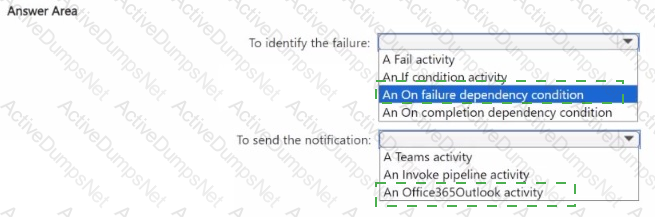
You need to ensure that the data engineers are notified if any step in populating the lakehouses fails. The solution must meet the technical requirements and minimize development effort.
What should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You need to recommend a solution for handling old files. The solution must meet the technical requirements. What should you include in the recommendation?
You need to populate the MAR1 data in the bronze layer.
Which two types of activities should you include in the pipeline? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You need to schedule the population of the medallion layers to meet the technical requirements.
What should you do?
You have an Azure key vault named KeyVaultl that contains secrets.
You have a Fabric workspace named Workspace-!. Workspace! contains a notebook named Notebookl that performs the following tasks:
• Loads stage data to the target tables in a lakehouse
• Triggers the refresh of a semantic model
You plan to add functionality to Notebookl that will use the Fabric API to monitor the semantic model refreshes. You need to retrieve the registered application ID and secret from KeyVaultl to generate the authentication token.
Solution: You use the following code segment:
Use notebookutils.credentials.getSecret and specify the key vault URL and key vault secret. Does this meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric eventstream that loads data into a table named Bike_Location in a KQL database. The table contains the following columns:
BikepointID
Street
Neighbourhood
No_Bikes
No_Empty_Docks
Timestamp
You need to apply transformation and filter logic to prepare the data for consumption. The solution must return data for a neighbourhood named Sands End when No_Bikes is at least 15. The results must be ordered by No_Bikes in ascending order.
Solution: You use the following code segment:

Does this meet the goal?
You have a Fabric lakehouse that contains the resources shown in the following table.

You need to use a notebook to query for customers in the United States and load the filtered data into USCustomers. The solution must minimize the number of scripts used.
Which statement should you use?
You are developing a data engineering solution in Fabric by using Apache Spark.
You need to monitor the performance of Spark workloads the solution must meet the following requirements
• Provide comprehensive information about the performance of the data engineering workloads.
• Identify stages and tasks that run slowly.
• Minimize administrative effort
What should you use?
You have a Fabric data warehouse that contains the following tables.
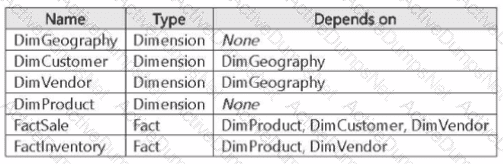
You need to refresh the tables by using an automated pipeline. The solution must ensure that table updates occur in the correct order to maintain referential integrity.
Which two tables should you refresh first? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You have a Fabric workspace named Workspace1 that contains three notebooks named notebook_01, notebook_02, and notebook_03.
You are building a new notebook in Workspace1 that will contain the following Directed Acyclic Graph (DAG) definition.

You need to modify the DAG definition to meet the following requirements:
• Ensure that notebook.01 and notebook_02 run in parallel.
• Ensure that notebook_02 only runs after the execution of notebook_03 is complete.
How should you modify the DAG definition?
You have a Fabric workspace that contains a lakehouse named Lakehouse1. Lakehouse1 contains a Delta table named Table1.
You analyze Table1 and discover that Table1 contains 2,000 Parquet files of 1 MB each.
You need to minimize how long it takes to query Table1.
What should you do?
DRAG DROP
You have a Fabric eventhouse that contains a KQL database. The database contains a table named TaxiData. The following is a sample of the data in TaxiData.
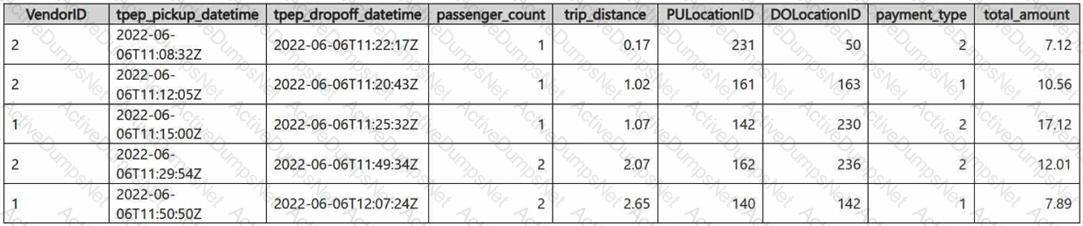
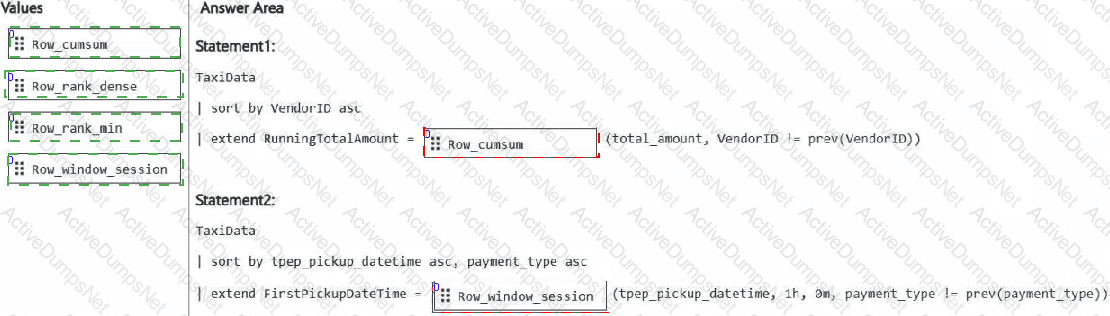
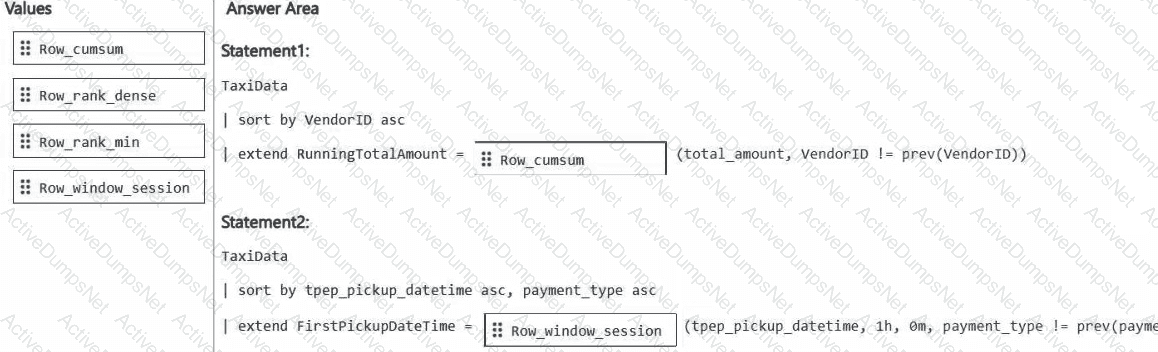
You need to build two KQL queries. The solution must meet the following requirements:
One of the queries must partition RunningTotalAmount by VendorID.
The other query must create a column named FirstPickupDateTime that shows the first value of each hour from tpep_pickup_datetime partitioned by payment_type.
How should you complete each query? To answer, drag the appropriate values the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.



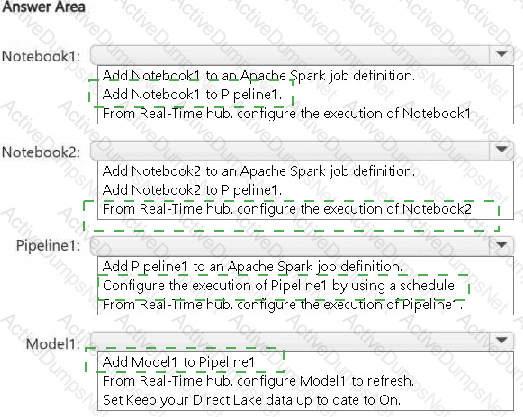
You have a Fabric workspace named Workspace1 that contains the items shown in the following table.
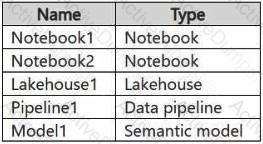
For Model1, the Keep your Direct Lake data up to date option is disabled.
You need to configure the execution of the items to meet the following requirements:
Notebook1 must execute every weekday at 8:00 AM.
Notebook2 must execute when a file is saved to an Azure Blob Storage container.
Model1 must refresh when Notebook1 has executed successfully.
How should you orchestrate each item? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

HOTSPOT
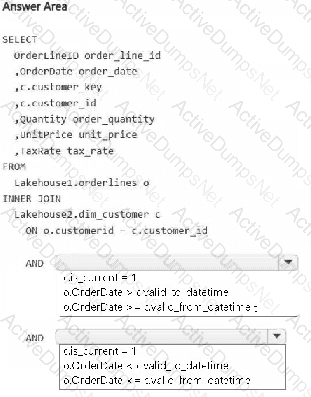
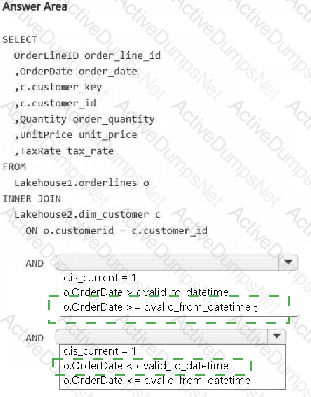
You have a Fabric workspace that contains two lakehouses named Lakehouse1 and Lakehouse2. Lakehouse1 contains staging data in a Delta table named Orderlines. Lakehouse2 contains a Type 2 slowly changing dimension (SCD) dimension table named Dim_Customer.
You need to build a query that will combine data from Orderlines and Dim_Customer to create a new fact table named Fact_Orders. The new table must meet the following requirements:
Enable the analysis of customer orders based on historical attributes.
Enable the analysis of customer orders based on the current attributes.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You have a Fabric F32 capacity that contains a workspace. The workspace contains a warehouse named DW1 that is modelled by using MD5 hash surrogate keys.
DW1 contains a single fact table that has grown from 200 million rows to 500 million rows during the past year.
You have Microsoft Power BI reports that are based on Direct Lake. The reports show year-over-year values.
Users report that the performance of some of the reports has degraded over time and some visuals show errors.
You need to resolve the performance issues. The solution must meet the following requirements:
Provide the best query performance.
Minimize operational costs.
Which should you do?
You have a Fabric workspace that contains an eventstream named EventStreaml. EventStreaml outputs events to a table named Tablel in a lakehouse. The streaming data is souiced from motorway sensors and represents the speed of cars.
You need to add a transformation to EventStream1 to average the car speeds. The speeds must be grouped by non-overlapping and contiguous time intervals of one minute. Each event must belong to exactly one window.
Which windowing function should you use?
You have a Fabric workspace that contains a lakehouse named Lakehouse1. Data is ingested into Lakehouse1 as one flat table. The table contains the following columns.

You plan to load the data into a dimensional model and implement a star schema. From the original flat table, you create two tables named FactSales and DimProduct. You will track changes in DimProduct.
You need to prepare the data.
Which three columns should you include in the DimProduct table? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.