Google Professional-Cloud-Developer Google Certified Professional - Cloud Developer Exam Practice Test
Total 265 questions
Google Certified Professional - Cloud Developer Questions and Answers
In order to meet their business requirements, how should HipLocal store their application state?
For this question, refer to the HipLocal case study.
HipLocal is expanding into new locations. They must capture additional data each time the application is launched in a new European country. This is causing delays in the development process due to constant schema changes and a lack of environments for conducting testing on the application changes. How should they resolve the issue while meeting the business requirements?
For this question, refer to the HipLocal case study.
HipLocal's application uses Cloud Client Libraries to interact with Google Cloud. HipLocal needs to configure authentication and authorization in the Cloud Client Libraries to implement least privileged access for the application. What should they do?
For this question, refer to the HipLocal case study.
How should HipLocal increase their API development speed while continuing to provide the QA team with a stable testing environment that meets feature requirements?
HipLocal wants to reduce the number of on-call engineers and eliminate manual scaling.
Which two services should they choose? (Choose two.)
For this question, refer to the HipLocal case study.
How should HipLocal redesign their architecture to ensure that the application scales to support a large increase in users?
For this question refer to the HipLocal case study.
HipLocal wants to reduce the latency of their services for users in global locations. They have created read replicas of their database in locations where their users reside and configured their service to read traffic using those replicas. How should they further reduce latency for all database interactions with the least amount of effort?
HipLocal's APIs are showing occasional failures, but they cannot find a pattern. They want to collect some
metrics to help them troubleshoot.
What should they do?
Which service should HipLocal use for their public APIs?
HipLocal is configuring their access controls.
Which firewall configuration should they implement?
HipLocal's.net-based auth service fails under intermittent load.
What should they do?
For this question, refer to the HipLocal case study.
A recent security audit discovers that HipLocal’s database credentials for their Compute Engine-hosted MySQL databases are stored in plain text on persistent disks. HipLocal needs to reduce the risk of these credentials being stolen. What should they do?
HipLocal wants to improve the resilience of their MySQL deployment, while also meeting their business and technical requirements.
Which configuration should they choose?
HipLocal has connected their Hadoop infrastructure to GCP using Cloud Interconnect in order to query data stored on persistent disks.
Which IP strategy should they use?
In order for HipLocal to store application state and meet their stated business requirements, which database service should they migrate to?
HipLocal’s data science team wants to analyze user reviews.
How should they prepare the data?
Which database should HipLocal use for storing user activity?
For this question, refer to the HipLocal case study.
Which Google Cloud product addresses HipLocal’s business requirements for service level indicators and objectives?
Which service should HipLocal use to enable access to internal apps?
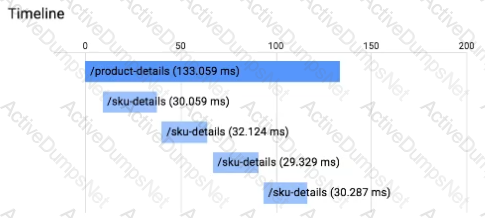
You have an application running in App Engine. Your application is instrumented with Stackdriver Trace. The /product-details request reports details about four known unique products at /sku-details as shown below. You want to reduce the time it takes for the request to complete. What should you do?
You manage an application that runs in a Compute Engine instance. You also have multiple backend services executing in stand-alone Docker containers running in Compute Engine instances. The Compute Engine instances supporting the backend services are scaled by managed instance groups in multiple regions. You want your calling application to be loosely coupled. You need to be able to invoke distinct service implementations that are chosen based on the value of an HTTP header found in the request. Which Google Cloud feature should you use to invoke the backend services?
You are a developer at a large organization. You have an application written in Go running in a production Google Kubernetes Engine (GKE) cluster. You need to add a new feature that requires access to BigQuery. You want to grant BigQuery access to your GKE cluster following Google-recommended best practices. What should you do?
You are writing a single-page web application with a user-interface that communicates with a third-party API
for content using XMLHttpRequest. The data displayed on the UI by the API results is less critical than other
data displayed on the same web page, so it is acceptable for some requests to not have the API data
displayed in the UI. However, calls made to the API should not delay rendering of other parts of the user
interface. You want your application to perform well when the API response is an error or a timeout.
What should you do?
You are developing an application that will be launched on Compute Engine instances into multiple distinct projects, each corresponding to the environments in your software development process (development, QA, staging, and production). The instances in each project have the same application code but a different configuration. During deployment, each instance should receive the application’s configuration based on the environment it serves. You want to minimize the number of steps to configure this flow.
What should you do?
You have decided to migrate your Compute Engine application to Google Kubernetes Engine. You need to build a container image and push it to Artifact Registry using Cloud Build. What should you do? (Choose two.)
A)
Run gcloud builds submit in the directory that contains the application source code.
B)
Run gcloud run deploy app-name --image gcr.io/$PROJECT_ID/app-name in the directory that contains the application source code.
C)
Run gcloud container images add-tag gcr.io/$PROJECT_ID/app-name gcr.io/$PROJECT_ID/app-name:latest in the directory that contains the application source code.
D)
In the application source directory, create a file named cloudbuild.yaml that contains the following contents:

E)
In the application source directory, create a file named cloudbuild.yaml that contains the following contents:

You recently deployed your application in Google Kubernetes Engine, and now need to release a new version of your application. You need the ability to instantly roll back to the previous version in case there are issues with the new version. Which deployment model should you use?
You are working on a new application that is deployed on Cloud Run and uses Cloud Functions Each time new features are added, new Cloud Functions and Cloud Run services are deployed You use ENV variables to keep track of the services and enable interservice communication but the maintenance of the ENV variables has become difficult. You want to implement dynamic discovery in a scalable way. What should you do?
You are developing an ecommerce web application that uses App Engine standard environment and Memorystore for Redis. When a user logs into the app, the application caches the user’s information (e.g., session, name, address, preferences), which is stored for quick retrieval during checkout.
While testing your application in a browser, you get a 502 Bad Gateway error. You have determined that the application is not connecting to Memorystore. What is the reason for this error?
You are porting an existing Apache/MySQL/PHP application stack from a single machine to Google Kubernetes Engine. You need to determine how to containerize the application. Your approach should follow Google-recommended best practices for availability. What should you do?
You need to load-test a set of REST API endpoints that are deployed to Cloud Run. The API responds to HTTP POST requests Your load tests must meet the following requirements:
• Load is initiated from multiple parallel threads
• User traffic to the API originates from multiple source IP addresses.
• Load can be scaled up using additional test instances
You want to follow Google-recommended best practices How should you configure the load testing'?
You are designing a schema for a Cloud Spanner customer database. You want to store a phone number array field in a customer table. You also want to allow users to search customers by phone number. How should you design this schema?
You need to configure a Deployment on Google Kubernetes Engine (GKE). You want to include a check that verifies that the containers can connect to the database. If the Pod is failing to connect, you want a script on the container to run to complete a graceful shutdown. How should you configure the Deployment?
Your data is stored in Cloud Storage buckets. Fellow developers have reported that data downloaded from Cloud Storage is resulting in slow API performance. You want to research the issue to provide details to the GCP support team. Which command should you run?
You have two tables in an ANSI-SQL compliant database with identical columns that you need to quickly
combine into a single table, removing duplicate rows from the result set.
What should you do?
You manage your company's ecommerce platform's payment system, which runs on Google Cloud. Your company must retain user logs for 1 year for internal auditing purposes and for 3 years to meet compliance requirements. You need to store new user logs on Google Cloud to minimize on-premises storage usage and ensure that they are easily searchable. You want to minimize effort while ensuring that the logs are stored correctly. What should you do?
Your development team has been asked to refactor an existing monolithic application into a set of composable microservices. Which design aspects should you implement for the new application? (Choose two.)
You are developing an ecommerce application that stores customer, order, and inventory data as relational tables inside Cloud Spanner. During a recent load test, you discover that Spanner performance is not scaling linearly as expected. Which of the following is the cause?
You recently developed a new service on Cloud Run. The new service authenticates using a custom service and then writes transactional information to a Cloud Spanner database. You need to verify that your application can support up to 5,000 read and 1,000 write transactions per second while identifying any bottlenecks that occur. Your test infrastructure must be able to autoscale. What should you do?
You are deploying a microservices application to Google Kubernetes Engine (GKE) that will broadcast livestreams. You expect unpredictable traffic patterns and large variations in the number of concurrent users. Your application must meet the following requirements:
• Scales automatically during popular events and maintains high availability
• Is resilient in the event of hardware failures
How should you configure the deployment parameters? (Choose two.)
You are a SaaS provider deploying dedicated blogging software to customers in your Google Kubernetes Engine (GKE) cluster. You want to configure a secure multi-tenant platform to ensure that each customer has access to only their own blog and can’t affect the workloads of other customers. What should you do?
Total 265 questions