Databricks Databricks-Machine-Learning-Professional Databricks Certified Machine Learning Professional Exam Practice Test
Total 60 questions
Databricks Certified Machine Learning Professional Questions and Answers
A machine learning engineer is converting a Hyperopt-based hyperparameter tuning process from manual MLflow logging to MLflow Autologging. They are trying to determine how to manage nested Hyperopt runs with MLflow Autologging.
Which of the following approaches will create a single parent run for the process and a child run for each unique combination of hyperparameter values when using Hyperopt and MLflow Autologging?
A machine learning engineer has developed a model and registered it using the FeatureStoreClient fs. The model has model URI model_uri. The engineer now needs to perform batch inference on customer-level Spark DataFrame spark_df, but it is missing a few of the static features that were used when training the model. The customer_id column is the primary key of spark_df and the training set used when training and logging the model.
Which of the following code blocks can be used to compute predictions for spark_df when the missing feature values can be found in the Feature Store by searching for features by customer_id?
A data scientist is utilizing MLflow to track their machine learning experiments. After completing a series of runs for the experiment with experiment ID exp_id, the data scientist wants to programmatically work with the experiment run data in a Spark DataFrame. They have an active MLflow Client client and an active Spark session spark.
Which of the following lines of code can be used to obtain run-level results for exp_id in a Spark DataFrame?
A data scientist has computed updated feature values for all primary key values stored in the Feature Store table features. In addition, feature values for some new primary key values have also been computed. The updated feature values are stored in the DataFrame features_df. They want to replace all data in features with the newly computed data.
Which of the following code blocks can they use to perform this task using the Feature Store Client fs?
A)

B)

C)

D)

E)

A machine learning engineer is in the process of implementing a concept drift monitoring solution. They are planning to use the following steps:
1. Deploy a model to production and compute predicted values
2. Obtain the observed (actual) label values
3. _____
4. Run a statistical test to determine if there are changes over time
Which of the following should be completed as Step #3?
A machine learning engineer wants to programmatically create a new Databricks Job whose schedule depends on the result of some automated tests in a machine learning pipeline.
Which of the following Databricks tools can be used to programmatically create the Job?
Which of the following statements describes streaming with Spark as a model deployment strategy?
A data scientist has developed and logged a scikit-learn random forest model model, and then they ended their Spark session and terminated their cluster. After starting a new cluster, they want to review the feature_importances_ of the original model object.
Which of the following lines of code can be used to restore the model object so that feature_importances_ is available?
A machine learning engineering team wants to build a continuous pipeline for data preparation of a machine learning application. The team would like the data to be fully processed and made ready for inference in a series of equal-sized batches.
Which of the following tools can be used to provide this type of continuous processing?
A machine learning engineer has registered a sklearn model in the MLflow Model Registry using the sklearn model flavor with UI model_uri.
Which of the following operations can be used to load the model as an sklearn object for batch deployment?
Which of the following is a reason for using Jensen-Shannon (JS) distance over a Kolmogorov-Smirnov (KS) test for numeric feature drift detection?
Which of the following lists all of the model stages are available in the MLflow Model Registry?
Which of the following describes the concept of MLflow Model flavors?
A machine learning engineer has created a webhook with the following code block:

Which of the following code blocks will trigger this webhook to run the associate job?
A)
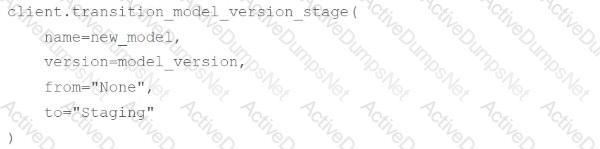
B)

C)

D)

E)

Which of the following is a benefit of logging a model signature with an MLflow model?
Which of the following describes the purpose of the context parameter in the predict method of Python models for MLflow?
Which of the following is a simple, low-cost method of monitoring numeric feature drift?
A machine learning engineer wants to view all of the active MLflow Model Registry Webhooks for a specific model.
They are using the following code block:
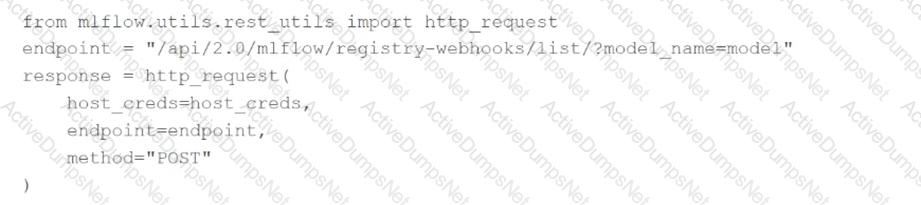
Which of the following changes does the machine learning engineer need to make to this code block so it will successfully accomplish the task?
Total 60 questions