Databricks Databricks-Certified-Data-Engineer-Associate Databricks Certified Data Engineer Associate Exam Exam Practice Test
Total 230 questions
Databricks Certified Data Engineer Associate Exam Questions and Answers
Which of the following describes the relationship between Gold tables and Silver tables?
A data engineer and data analyst are working together on a data pipeline. The data engineer is working on the raw, bronze, and silver layers of the pipeline using Python, and the data analyst is working on the gold layer of the pipeline using SQL. The raw source of the pipeline is a streaming input. They now want to migrate their pipeline to use Delta Live Tables.
Which of the following changes will need to be made to the pipeline when migrating to Delta Live Tables?
A data engineer has been using a Databricks SQL dashboard to monitor the cleanliness of the input data to an ELT job. The ELT job has its Databricks SQL query that returns the number of input records containing unexpected NULL values. The data engineer wants their entire team to be notified via a messaging webhook whenever this value reaches 100.
Which of the following approaches can the data engineer use to notify their entire team via a messaging webhook whenever the number of NULL values reaches 100?
A data engineer has configured a Structured Streaming job to read from a table, manipulate the data, and then perform a streaming write into a new table.
The code block used by the data engineer is below:

If the data engineer only wants the query to process all of the available data in as many batches as required, which of the following lines of code should the data engineer use to fill in the blank?
Identify the impact of ON VIOLATION DROP ROW and ON VIOLATION FAIL UPDATE for a constraint violation.
A data engineer has created an ETL pipeline using Delta Live table to manage their company travel reimbursement detail, they want to ensure that the if the location details has not been provided by the employee, the pipeline needs to be terminated.
How can the scenario be implemented?
Which Databricks SQL predicate correctly performs a null-safe equality comparison so that rows are matched when both sides are NULL or when both are equal non-NULL values?
A data engineer needs to apply custom logic to identify employees with more than 5 years of experience in array column employees in table stores. The custom logic should create a new column exp_employees that is an array of all of the employees with more than 5 years of experience for each row. In order to apply this custom logic at scale, the data engineer wants to use the FILTER higher-order function.
Which of the following code blocks successfully completes this task?

Which of the following approaches should be used to send the Databricks Job owner an email in the case that the Job fails?
A data engineer is managing a data pipeline in Databricks, where multiple Delta tables are used for various transformations. The team wants to track how data flows through the pipeline, including identifying dependencies between Delta tables, notebooks, jobs, and dashboards. The data engineer is utilizing the Unity Catalog lineage feature to monitor this process.
How does Unity Catalog’s data lineage feature support the visualization of relationships between Delta tables, notebooks, jobs, and dashboards?
A departing platform owner currently holds ownership of multiple catalogs and controls storage credentials and external locations. The data engineer wants to ensure continuity: transfer catalog ownership to the platform team group, delegate ongoing privilege management, and retain the ability to receive and share data via Delta Sharing .
Which role must be in place to perform these actions across the metastore?
An organization is looking for an optimized storage layer that supports ACID transactions and schema enforcement. Which technology should the organization use?
A data engineer is developing a small proof of concept in a notebook. When running the entire notebook, cluster usage spikes. The data engineer wants to keep the development experience and get real-time results.
Which cluster meets these requirements?
A data engineer needs access to a table new_uable, but they do not have the correct permissions. They can ask the table owner for permission, but they do not know who the table owner is.
Which approach can be used to identify the owner of new_table?
A data engineer triggers a scheduled job but finds that the new run was not executed. The run history shows that the run was skipped with a concurrency-related queue message.
Which configuration should the engineer investigate?
A data engineer is transforming a Bronze table containing API-response data into a Silver table. The Bronze table has a user_profile column of type STRING that contains JSON data. An example value is:
{ " user_id " : " 12345 " , " name " : " John Smith " , " age " :32, " email " : " john@example.com " }
The Silver table must make this data easily queryable for analytics without requiring JSON parsing in every downstream query.
Which approach standardizes this column for the Silver table?
A new data engineering team has been assigned to work on a project. The team will need access to database customers in order to see what tables already exist. The team has its own group team.
Which of the following commands can be used to grant the necessary permission on the entire database to the new team?
A data engineer uploads a CSV file using the Create or modify a table using file upload option in Databricks. To avoid incorrect schema inference, the engineer disables Automatically detect column types before creating a Unity Catalog-managed table.
What is the outcome?
A data engineer works for an organization that must meet a stringent Service Level Agreement (SLA) that demands minimal runtime errors and high availability for its data processing pipelines. The data engineer wants to avoid the operational overhead of managing and tuning clusters.
Which architectural solution will meet the requirements?
Which single Databricks CLI command deploys local bundle assets to the target workspace specified in the bundle configuration file?
A data engineer needs to enforce row-level security on main.secure.events(region STRING, event_id STRING). Members of the account group all_regions must see all rows. All other users must see only rows where region = ' EU ' .
Which SQL sequence satisfies the requirement?
A data engineer manages multiple external tables linked to various data sources. The data engineer wants to manage these external tables efficiently and ensure that only the necessary permissions are granted to users for accessing specific external tables.
How should the data engineer manage access to these external tables?
A data engineer is setting up access control in Unity Catalog and needs to ensure that a group of data analysts can query tables but not modify data.
Which permission should the data engineer grant to the data analysts?
Which tool is used by Auto Loader to process data incrementally?
A data engineer needs to conduct Exploratory Data Analysis (EDA) on data residing in a database within the company’s custom-defined cloud network . The data engineer is using SQL for this task.
Which type of SQL Warehouse will enable the data engineer to process large numbers of queries quickly and cost-effectively?
A data engineer is writing a script that is meant to ingest new data from cloud storage. In the event of the Schema change, the ingestion should fail. It should fail until the changes downstream source can be found and verified as intended changes.
Which command will meet the requirements?
A data engineer is setting up a new Databricks pipeline that ingests clickstream events from Kafka and daily product catalogs from cloud object storage. To ensure auditability and easy reprocessing, the engineer wants to land all source data first. Later stages will handle cleaning, deduplication, and business modeling before the data is used in dashboards.
Which approach aligns with Medallion Architecture principles?
A data engineer needs to conduct Exploratory Analysis on data residing in a database that is within the company ' s custom-defined network in the cloud. The data engineer is using SQL for this task.
Which type of SQL Warehouse will enable the data engineer to process large numbers of queries quickly and cost-effectively?
A data engineer is building a nightly batch ETL pipeline that processes very large volumes of raw JSON logs from a data lake into Delta tables for reporting. The data arrives in bulk once per day, and the pipeline takes several hours to complete. Cost efficiency is important , but performance and reliable completion of the pipeline are the highest priorities.
Which type of Databricks cluster should the data engineer configure?
A data engineer has multiple Unity Catalog-managed Delta tables that require regular maintenance. Currently, the engineer manually schedules OPTIMIZE and VACUUM jobs for each table, adjusting their frequency according to how often each table is queried and updated.
The engineer needs to eliminate this manual maintenance overhead and allow Databricks to determine automatically when and how to run these operations.
Which action should the engineer take?
A data engineer is configuring Unity Catalog in Databricks and needs to assign a role to a user who should have the ability to grant and revoke privileges on various data objects within a specific schema but should not have read/write access over the schema or its objects.
Which role should the data engineer assign to this user?
A data engineer has developed a Python notebook in a Databricks workspace and configured it to run as a scheduled job to process daily sales data.
How are the storage and execution of this notebook managed within the Databricks architecture?
Which two components function in the DB platform architecture’s control plane? (Choose two.)
A pipeline uses COPY INTO to ingest CSV files from cloud object storage into a Unity Catalog Delta table. Some files are occasionally re-uploaded with corrections using the same filename.
The engineer needs the corrected data to be ingested as soon as it becomes available.
What should the engineer do?
A data engineer wants to create a data entity from a couple of tables. The data entity must be used by other data engineers in other sessions. It also must be saved to a physical location.
Which of the following data entities should the data engineer create?
A data engineer wants to delegate day-to-day permission management for the schema main.marketing to the mkt-admins group, without making them workspace admins. They should be able to grant and revoke privileges for other users on objects within that schema.
Which approach aligns with Unity Catalog’s ownership and privilege model?
A data engineer is preparing a Declarative Automation Bundle, formerly known as a Databricks Asset Bundle, to deploy a Lakeflow pipeline.
To ensure that the pipeline is deployed to the correct environment, where should workspace-specific configurations, such as the workspace host URL and root storage path, be defined within the bundle project?
A data engineer needs to apply custom logic to string column city in table stores for a specific use case. In order to apply this custom logic at scale, the data engineer wants to create a SQL user-defined function (UDF).
Which of the following code blocks creates this SQL UDF?
A data engineer has realized that the data files associated with a Delta table are incredibly small. They want to compact the small files to form larger files to improve performance.
Which of the following keywords can be used to compact the small files?
Which of the following tools is used by Auto Loader process data incrementally?
Which of the following benefits is provided by the array functions from Spark SQL?
A data engineer is reviewing the documentation on audit logs in Databricks for compliance purposes and needs to understand the format in which audit logs output events.
How are events formatted in Databricks audit logs?
A data engineer ingests semi-structured JSON logs into a Delta table using Auto Loader with schema evolution enabled. A new string field named userAgent appears in the JSON source data.
What happens to the new userAgent field?
A data engineer has a Job with multiple tasks that runs nightly. Each of the tasks runs slowly because the clusters take a long time to start.
Which of the following actions can the data engineer perform to improve the start up time for the clusters used for the Job?
Which of the following is hosted completely in the control plane of the classic Databricks architecture?
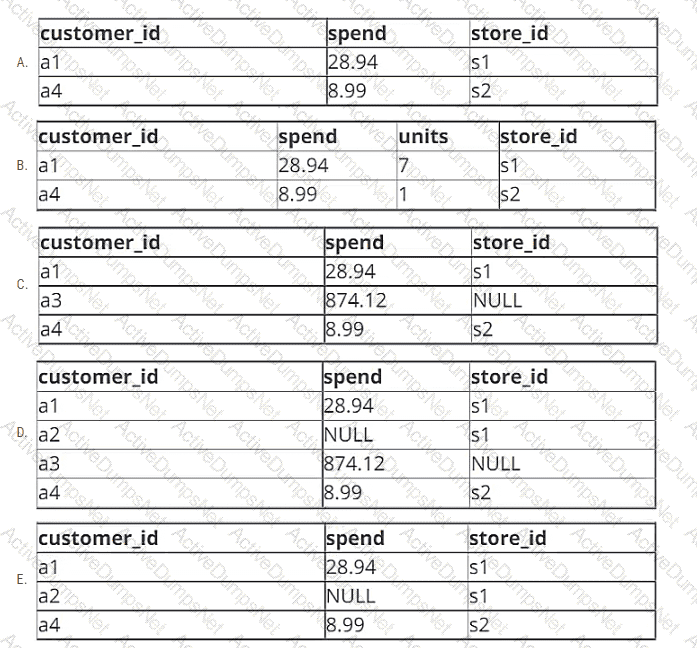
A data engineer is working with two tables. Each of these tables is displayed below in its entirety.

The data engineer runs the following query to join these tables together:

Which of the following will be returned by the above query?
A data engineer has manually created several Databricks jobs and dashboards using the workspace UI. The team now wants to manage these resources as code using Declarative Automation Bundles, formerly known as Databricks Asset Bundles, store the configuration in a Git repository, and deploy changes through CI/CD.
Which approach converts the existing resources into a bundle project?
What is the functionality of AutoLoader in Databricks?
An organization plans to share a large dataset stored in a Databricks workspace on AWS with a partner organization whose Databricks workspace is hosted on Azure. The data engineer wants to minimize data transfer costs while ensuring secure and efficient data sharing.
Which strategy will reduce data egress costs associated with cross-cloud data sharing?
A data engineer needs to ingest JSON change data from Salesforce into Unity Catalog-governed Delta tables using a low-code, fully managed experience.
Which Databricks capability should the data engineer use?
A data engineering team uses Declarative Automation Bundles, formerly known as Databricks Asset Bundles, to deploy the same codebase across development, test, and production environments. The team wants environment-specific behavior to be applied only through bundle configuration, without modifying notebooks, job definitions, or deployment logic during promotion.
Which approach applies environment-specific configuration while meeting this requirement?
A data engineer has a single-task Job that runs each morning before they begin working. After identifying an upstream data issue, they need to set up another task to run a new notebook prior to the original task.
Which of the following approaches can the data engineer use to set up the new task?
Which TWO items are characteristics of the Gold Layer?
Choose 2 answers
A dataset has been defined using Delta Live Tables and includes an expectations clause:
CONSTRAINT valid_timestamp EXPECT (timestamp > ' 2020-01-01 ' ) ON VIOLATION FAIL UPDATE
What is the expected behavior when a batch of data containing data that violates these constraints is processed?
Which of the following describes a benefit of creating an external table from Parquet rather than CSV when using a CREATE TABLE AS SELECT statement?
Which of the following describes the relationship between Bronze tables and raw data?
A data engineer has developed a data pipeline to ingest data from a JSON source using Auto Loader, but the engineer has not provided any type inference or schema hints in their pipeline. Upon reviewing the data, the data engineer has noticed that all of the columns in the target table are of the string type despite some of the fields only including float or boolean values.
Which of the following describes why Auto Loader inferred all of the columns to be of the string type?
A data engineer has been given a new record of data:
id STRING = ' a1 '
rank INTEGER = 6
rating FLOAT = 9.4
Which of the following SQL commands can be used to append the new record to an existing Delta table my_table?
An organization is building a data lakehouse and needs to ingest data from multiple sources into Unity Catalog-managed tables:
Salesforce: More than 50 objects, frequent schema changes, and OAuth authentication
An on-premises SQL Server database: More than 100 tables, CDC enabled, and private network connectivity required
Daily JSON files landing in Azure Data Lake Storage Gen2
The organization wants all ingested data governed by Unity Catalog, minimal engineering effort for schema changes, and serverless processing wherever possible.
Which ingestion strategy meets these requirements?
A data engineer has a PySpark DataFrame named events_df with the following schema:
event_id STRING,
device STRUCT <
id: STRING,
model: STRING,
location: STRUCT <
latitude: DOUBLE,
longitude: DOUBLE
>
> ,
event_ts TIMESTAMP
The engineer needs to flatten all nested device fields into root-level columns while retaining the event identifier and timestamp.
Which PySpark expression achieves this requirement?
A data engineer is inspecting an ETL pipeline based on a Pyspark job that consistently encounters performance bottlenecks. Based on developer feedback, the data engineer assumes the job is low on compute resources. To pinpoint the issue, the data engineer observes the Spark Ul and finds out the job has a high CPU time vs Task time.
Which course of action should the data engineer take?
A data engineer wants to create a relational object by pulling data from two tables. The relational object does not need to be used by other data engineers in other sessions. In order to save on storage costs, the data engineer wants to avoid copying and storing physical data.
Which of the following relational objects should the data engineer create?
A data engineer runs df.toPandas() on a wide DataFrame containing 50 million rows. The notebook cell fails with a java.lang.OutOfMemoryError on the driver.
Which memory configuration is directly associated with this failure?
A data engineer is cleaning a Bronze table. The requirement is to eliminate rows where either the customer_email field or the customer_phone field is NULL. The cleaning must be performed in one operation using a single method call.
Which PySpark approach supports filtering multiple columns for NULL values in one call?
A data engineering team is designing the Gold layer in its Unity Catalog-governed lakehouse for downstream BI and analytics users. The team wants to expose business-ready metrics with fast query performance and consistent definitions while keeping the transformation logic in Spark notebooks.
Which type of Gold-layer object meets this requirement?
A data engineer is attempting to write Python and SQL in the same command cell and is running into an error The engineer thought that it was possible to use a Python variable in a select statement.
Why does the command fail?
Which SQL keyword can be used to convert a table from a long format to a wide format?
What Databricks feature can be used to check the data sources and tables used in a workspace?
A data engineer has a Job that has a complex run schedule, and they want to transfer that schedule to other Jobs.
Rather than manually selecting each value in the scheduling form in Databricks, which of the following tools can the data engineer use to represent and submit the schedule programmatically?
Which of the following must be specified when creating a new Delta Live Tables pipeline?
Total 230 questions