Databricks Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 Databricks Certified Associate Developer for Apache Spark 3.5 – Python Exam Practice Test
Databricks Certified Associate Developer for Apache Spark 3.5 – Python Questions and Answers
A data engineer is working on a real-time analytics pipeline using Apache Spark Structured Streaming. The engineer wants to process incoming data and ensure that triggers control when the query is executed. The system needs to process data in micro-batches with a fixed interval of 5 seconds.
Which code snippet the data engineer could use to fulfil this requirement?
A)

B)

C)

D)

Options:
2 of 55. Which command overwrites an existing JSON file when writing a DataFrame?
43 of 55.
An organization has been running a Spark application in production and is considering disabling the Spark History Server to reduce resource usage.
What will be the impact of disabling the Spark History Server in production?
A data scientist is working with a Spark DataFrame called customerDF that contains customer information. The DataFrame has a column named email with customer email addresses. The data scientist needs to split this column into username and domain parts.
Which code snippet splits the email column into username and domain columns?
30 of 55.
A data engineer is working on a num_df DataFrame and has a Python UDF defined as:
def cube_func(val):
return val * val * val
Which code fragment registers and uses this UDF as a Spark SQL function to work with the DataFrame num_df?
A developer wants to refactor some older Spark code to leverage built-in functions introduced in Spark 3.5.0. The existing code performs array manipulations manually. Which of the following code snippets utilizes new built-in functions in Spark 3.5.0 for array operations?

A)
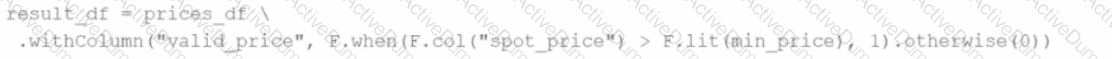
B)
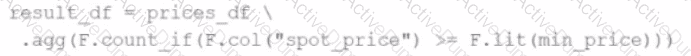
C)

D)

A developer is working with a pandas DataFrame containing user behavior data from a web application.
Which approach should be used for executing a groupBy operation in parallel across all workers in Apache Spark 3.5?
A)
Use the applylnPandas API
B)

C)

D)

A data engineer has been asked to produce a Parquet table which is overwritten every day with the latest data. The downstream consumer of this Parquet table has a hard requirement that the data in this table is produced with all records sorted by the market_time field.
Which line of Spark code will produce a Parquet table that meets these requirements?
Given a CSV file with the content:

And the following code:
from pyspark.sql.types import *
schema = StructType([
StructField("name", StringType()),
StructField("age", IntegerType())
])
spark.read.schema(schema).csv(path).collect()
What is the resulting output?
A developer is running Spark SQL queries and notices underutilization of resources. Executors are idle, and the number of tasks per stage is low.
What should the developer do to improve cluster utilization?
44 of 55.
A data engineer is working on a real-time analytics pipeline using Spark Structured Streaming.
They want the system to process incoming data in micro-batches at a fixed interval of 5 seconds.
Which code snippet fulfills this requirement?
An engineer has a large ORC file located at /file/test_data.orc and wants to read only specific columns to reduce memory usage.
Which code fragment will select the columns, i.e., col1, col2, during the reading process?
A Spark application developer wants to identify which operations cause shuffling, leading to a new stage in the Spark execution plan.
Which operation results in a shuffle and a new stage?
A data scientist at a financial services company is working with a Spark DataFrame containing transaction records. The DataFrame has millions of rows and includes columns for transaction_id, account_number, transaction_amount, and timestamp. Due to an issue with the source system, some transactions were accidentally recorded multiple times with identical information across all fields. The data scientist needs to remove rows with duplicates across all fields to ensure accurate financial reporting.
Which approach should the data scientist use to deduplicate the orders using PySpark?
A Spark DataFrame df is cached using the MEMORY_AND_DISK storage level, but the DataFrame is too large to fit entirely in memory.
What is the likely behavior when Spark runs out of memory to store the DataFrame?
28 of 55.
A data analyst builds a Spark application to analyze finance data and performs the following operations:
filter, select, groupBy, and coalesce.
Which operation results in a shuffle?
46 of 55.
A data engineer is implementing a streaming pipeline with watermarking to handle late-arriving records.
The engineer has written the following code:
inputStream \
.withWatermark("event_time", "10 minutes") \
.groupBy(window("event_time", "15 minutes"))
What happens to data that arrives after the watermark threshold?
41 of 55.
A data engineer is working on the DataFrame df1 and wants the Name with the highest count to appear first (descending order by count), followed by the next highest, and so on.
The DataFrame has columns:
id | Name | count | timestamp
---------------------------------
1 | USA | 10
2 | India | 20
3 | England | 50
4 | India | 50
5 | France | 20
6 | India | 10
7 | USA | 30
8 | USA | 40
Which code fragment should the engineer use to sort the data in the Name and count columns?
17 of 55.
A data engineer has noticed that upgrading the Spark version in their applications from Spark 3.0 to Spark 3.5 has improved the runtime of some scheduled Spark applications.
Looking further, the data engineer realizes that Adaptive Query Execution (AQE) is now enabled.
Which operation should AQE be implementing to automatically improve the Spark application performance?
55 of 55.
An application architect has been investigating Spark Connect as a way to modernize existing Spark applications running in their organization.
Which requirement blocks the adoption of Spark Connect in this organization?
A developer needs to produce a Python dictionary using data stored in a small Parquet table, which looks like this:

The resulting Python dictionary must contain a mapping of region -> region id containing the smallest 3 region_id values.
Which code fragment meets the requirements?
A)

B)

C)

D)

The resulting Python dictionary must contain a mapping of region -> region_id for the smallest 3 region_id values.
Which code fragment meets the requirements?
A data scientist is analyzing a large dataset and has written a PySpark script that includes several transformations and actions on a DataFrame. The script ends with a collect() action to retrieve the results.
How does Apache Spark™'s execution hierarchy process the operations when the data scientist runs this script?
Which configuration can be enabled to optimize the conversion between Pandas and PySpark DataFrames using Apache Arrow?
A data engineer is running a batch processing job on a Spark cluster with the following configuration:
10 worker nodes
16 CPU cores per worker node
64 GB RAM per node
The data engineer wants to allocate four executors per node, each executor using four cores.
What is the total number of CPU cores used by the application?
A data engineer is building an Apache Spark™ Structured Streaming application to process a stream of JSON events in real time. The engineer wants the application to be fault-tolerant and resume processing from the last successfully processed record in case of a failure. To achieve this, the data engineer decides to implement checkpoints.
Which code snippet should the data engineer use?
A data scientist is working on a project that requires processing large amounts of structured data, performing SQL queries, and applying machine learning algorithms. The data scientist is considering using Apache Spark for this task.
Which combination of Apache Spark modules should the data scientist use in this scenario?
Options:
A Spark developer is building an app to monitor task performance. They need to track the maximum task processing time per worker node and consolidate it on the driver for analysis.
Which technique should be used?
Given:
python
CopyEdit
spark.sparkContext.setLogLevel("
Which set contains the suitable configuration settings for Spark driver LOG_LEVELs?
A data engineer needs to write a Streaming DataFrame as Parquet files.
Given the code:

Which code fragment should be inserted to meet the requirement?
A)

B)

C)

D)

Which code fragment should be inserted to meet the requirement?
34 of 55.
A data engineer is investigating a Spark cluster that is experiencing underutilization during scheduled batch jobs.
After checking the Spark logs, they noticed that tasks are often getting killed due to timeout errors, and there are several warnings about insufficient resources in the logs.
Which action should the engineer take to resolve the underutilization issue?
9 of 55.
Given the code fragment:
import pyspark.pandas as ps
pdf = ps.DataFrame(data)
Which method is used to convert a Pandas API on Spark DataFrame (pyspark.pandas.DataFrame) into a standard PySpark DataFrame (pyspark.sql.DataFrame)?
13 of 55.
A developer needs to produce a Python dictionary using data stored in a small Parquet table, which looks like this:
region_id
region_name
10
North
12
East
14
West
The resulting Python dictionary must contain a mapping of region_id to region_name, containing the smallest 3 region_id values.
Which code fragment meets the requirements?
A data engineer wants to create an external table from a JSON file located at /data/input.json with the following requirements:
Create an external table named users
Automatically infer schema
Merge records with differing schemas
Which code snippet should the engineer use?
Options:
What is the benefit of Adaptive Query Execution (AQE)?
A Spark engineer must select an appropriate deployment mode for the Spark jobs.
What is the benefit of using cluster mode in Apache Spark™?
A data engineer wants to process a streaming DataFrame that receives sensor readings every second with columns sensor_id, temperature, and timestamp. The engineer needs to calculate the average temperature for each sensor over the last 5 minutes while the data is streaming.
Which code implementation achieves the requirement?
Options from the images provided:
A)

B)

C)
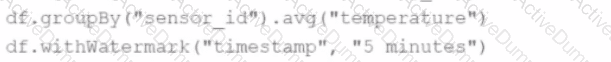
D)

Which UDF implementation calculates the length of strings in a Spark DataFrame?
An engineer notices a significant increase in the job execution time during the execution of a Spark job. After some investigation, the engineer decides to check the logs produced by the Executors.
How should the engineer retrieve the Executor logs to diagnose performance issues in the Spark application?
Given the schema:

event_ts TIMESTAMP,
sensor_id STRING,
metric_value LONG,
ingest_ts TIMESTAMP,
source_file_path STRING
The goal is to deduplicate based on: event_ts, sensor_id, and metric_value.
Options:
4 of 55.
A developer is working on a Spark application that processes a large dataset using SQL queries. Despite having a large cluster, the developer notices that the job is underutilizing the available resources. Executors remain idle for most of the time, and logs reveal that the number of tasks per stage is very low. The developer suspects that this is causing suboptimal cluster performance.
Which action should the developer take to improve cluster utilization?