Confluent CCDAK Confluent Certified Developer for Apache Kafka Certification Examination Exam Practice Test
Confluent Certified Developer for Apache Kafka Certification Examination Questions and Answers
You are writing a producer application and need to ensure proper delivery. You configure the producer with acks=all.
Which two actions should you take to ensure proper error handling?
(Select two.)
Which two statements about Kafka Connect Single Message Transforms (SMTs) are correct?
(Select two.)
You are working on a Kafka cluster with three nodes. You create a topic named orders with:
replication.factor = 3
min.insync.replicas = 2
acks = allWhat exception will be generated if two brokers are down due to network delay?
Match the testing tool with the type of test it is typically used to perform.
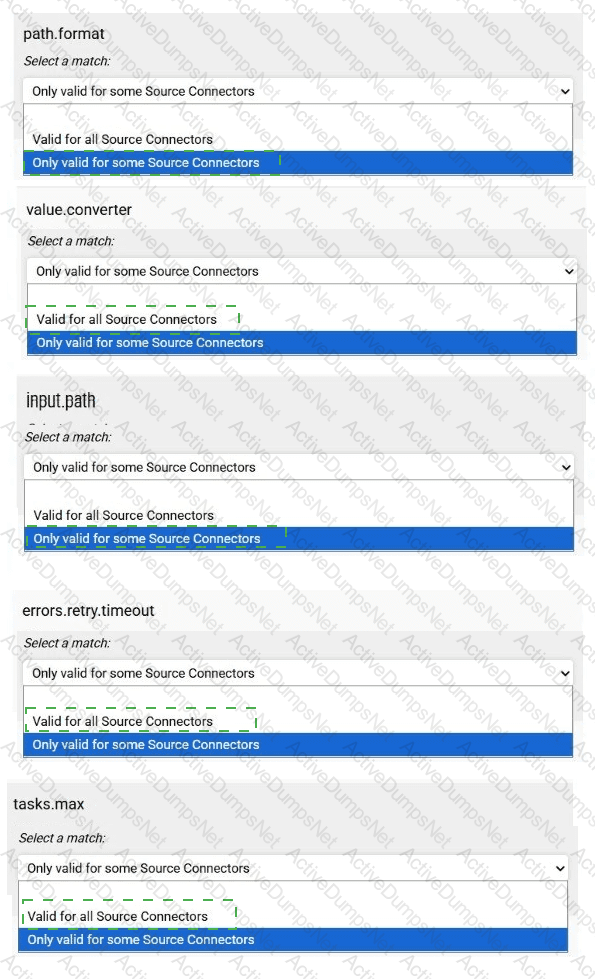
Match each configuration parameter with the correct option.
To answer choose a match for each option from the drop-down. Partial
credit is given for each correct answer.

(You need to send a JSON message on the wire. The message key is a string.
How would you do this?)
You need to explain the best reason to implement the consumer callback interface ConsumerRebalanceListener prior to a Consumer Group Rebalance.
Which statement is correct?
(You are implementing a Kafka Streams application to process financial transactions.
Each transaction must be processed exactly once to ensure accuracy.
The application reads from an input topic, performs computations, and writes results to an output topic.
During testing, you notice duplicate entries in the output topic, which violates the exactly-once processing requirement.
You need to ensure exactly-once semantics (EOS) for this Kafka Streams application.
Which step should you take?)
(You create an Orders topic with 10 partitions.
The topic receives data at high velocity.
Your Kafka Streams application initially runs on a server with four CPU threads.
You move the application to another server with 10 CPU threads to improve performance.
What does this example describe?)
(You started a new Kafka Connect worker.
Which configuration identifies the Kafka Connect cluster that your worker will join?)
You have a topic t1 with six partitions. You use Kafka Connect to send data from topic t1 in your Kafka cluster to Amazon S3. Kafka Connect is configured for two tasks.
How many partitions will each task process?
(You deploy a Kafka Streams application with five application instances.
Kafka Streams stores application metadata using internal topics.
Auto-topic creation is disabled in the Kafka cluster.
Which statement about this scenario is true?)
(What are two stateless operations in the Kafka Streams API?
Select two.)
Which partition assignment minimizes partition movements between two assignments?
Which two producer exceptions are examples of the class RetriableException? (Select two.)
Which two statements are correct about transactions in Kafka?
(Select two.)
You are composing a REST request to create a new connector in a running Connect cluster. You invoke POST /connectors with a configuration and receive a 409 (Conflict) response.
What are two reasons for this response? (Select two.)
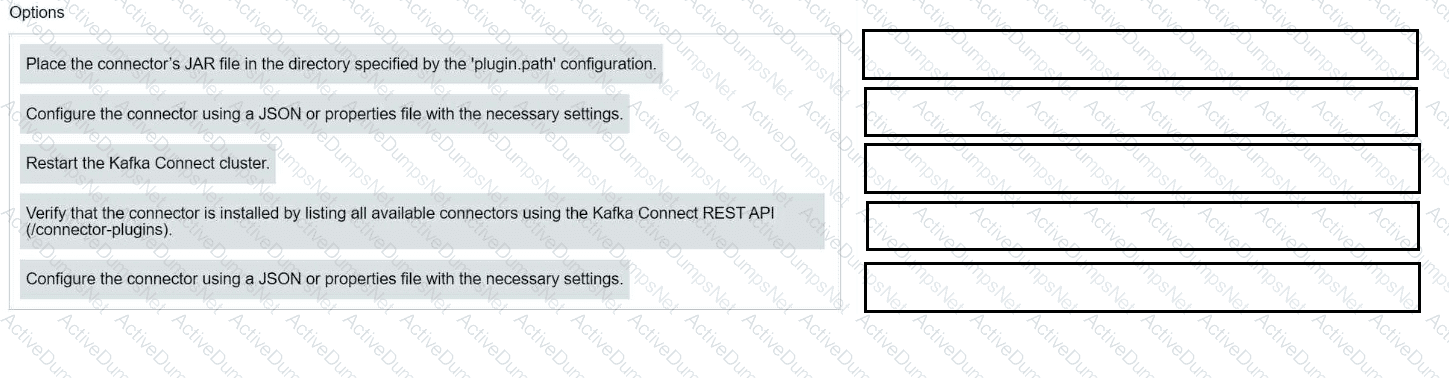
Match each configuration parameter with the correct deployment step in installing a Kafka connector.

Which is true about topic compaction?
Which two statements are correct when assigning partitions to the consumers in a consumer group using the assign() API?
(Select two.)
Where are source connector offsets stored?
What are two examples of performance metrics?
(Select two.)
(You are developing a Kafka Streams application with a complex topology that has multiple sources, processors, sinks, and sub-topologies.
You are working in a development environment and do not have access to a real Kafka cluster or topics.
You need to perform unit testing on your Kafka Streams application.
Which should you use?)
Your application is consuming from a topic with one consumer group.
The number of running consumers is equal to the number of partitions.
Application logs show that some consumers are leaving the consumer group during peak time, triggering a rebalance. You also notice that your application is processing many duplicates.
You need to stop consumers from leaving the consumer group.
What should you do?
(You have a topic with four partitions. The application reading this topic is using a consumer group with two consumers.
Throughput is smoothly distributed among partitions, but application lag is increasing.
Application monitoring shows that message processing is consuming all available CPU resources.
Which action should you take to resolve this issue?)
(You need to set alerts on key broker metrics to trigger notifications when a Kafka cluster is unhealthy.
What are three minimum broker metrics to monitor for cluster health?
Select three.)
(A consumer application needs to use an at-most-once delivery semantic.
What is the best consumer configuration and code skeleton to avoid duplicate messages being read?)