Which of the following types of layers is used to downsample feature detection when using a convolutional neural network?
Which of the following image data augmentation techniques allows a data scientist to increase the size of a data set?
Which of the following does k represent in the k-means model?
Which of the following is the naive assumption in Bayes' rule?
Which of the following measures would a data scientist most likely use to calculate the similarity of two text strings?
An analyst is examining data from an array of temperature sensors and sees that one sensor consistently returns values that are much higher than the values from the other sensors. Which of the following terms best describes this type of error?
Which of the following modeling tools is appropriate for solving a scheduling problem?
A data analyst is examining the correlation matrix of a new data set to identify issues that could adversely impact model performance. Which of the following is the analyst most likely checking for?
In a modeling project, people evaluate phrases and provide reactions as the target variable for the model. Which of the following best describes what this model is doing?
A data scientist is preparing to brief a non-technical audience that is focused on analysis and results. During the modeling process, the data scientist produced the following artifacts:
Which of the following artifacts should the data scientist include in the briefing? (Choose two.)
A company created a very popular collectible card set. Collectors attempt to collect the entire set, but the availability of each card varies, because some cards have higher production volumes than others. The set contains a total of 12 cards. The attributes of the cards are shown.
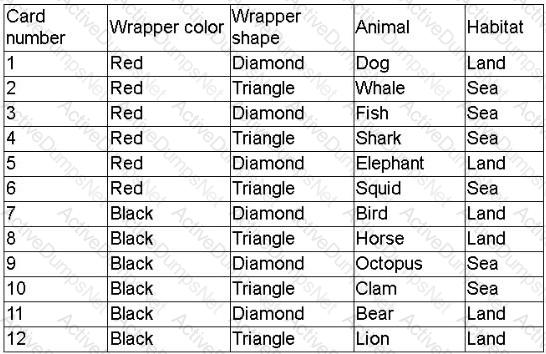
The data scientist is tasked with designing an initial model iteration to predict whether the animal on the card lives in the sea or on land, given the card's features: Wrapper color, Wrapper shape, and Animal.
Which of the following is the best way to accomplish this task?
Given matrix
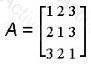
Which of the following is AT?




A team is building a spam detection system. The team wants a probability-based identification method without complex, in-depth training from the historical data set. Which of the following methods would best serve this purpose?
Which of the following techniques enables automation and iteration of code releases?
A data scientist is deploying a model that needs to be accessed by multiple departments with minimal development effort by the departments. Which of the following APIs would be best for the data scientist to use?
Which of the following compute delivery models allows packaging of only critical dependencies while developing a reusable asset?
Given the equation:
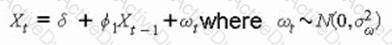
Xt = δ + ϕ1Xt−1 + ωt, where ωt ∼ N(0, σω²)
Which of the following time series models best represents this process?
A data scientist is working with a data set that covers a two-year period for a large number of machines. The data set contains:
Machine system ID numbers
Sensor measurement values
Daily timestamps for each machine
The data scientist needs to plot the total measurements from all the machines over the entire time period. Which of the following is the best way to present this data?
A data scientist uses a large data set to build multiple linear regression models to predict the likely market value of a real estate property. The selected new model has an RMSE of 995 on the holdout set and an adjusted R² of 0.75. The benchmark model has an RMSE of 1,000 on the holdout set. Which of the following is the best business statement regarding the new model?
A data scientist is analyzing a data set with categorical features and would like to make those features more useful when building a model. Which of the following data transformation techniques should the data scientist use? (Choose two.)
A data analyst wants to find the latitude and longitude of a mailing address. Which of the following is the best method to use?
Which of the following distributions would be best to use for hypothesis testing on a data set with 20 observations?
Which of the following is the layer that is responsible for the depth in deep learning?
A data scientist has built a model that provides the likelihood of an error occurring in a factory. The historical accuracy of the model is 90%. At a specific factory, the model is reporting a likelihood score of 0.90. Which of the following explains a confidence score of 0.90?
A data analyst wants to generate the most data using tables from a database. Which of the following is the best way to accomplish this objective?